1) L’Information Retrieval
L’Information Retrieval (IR) è la scienza che si occupa della rappresentazione, registrazione e ricerca delle informazioni. Le informazioni sono in genere di tipo testuale, ma possono anche essere di tipo multimediale, come immagini, suoni, video, ecc.
La storia dell’Information Retrieval è iniziata con la nascita delle prime grandi civiltà umane. L’archiviazione e la ricerca delle informazioni erano attività presenti già nelle antiche civiltà dei Sumeri, Babilonesi, Egizi, Greci.
I sistemi IR sono nati inizialmente per gestire collezioni di documenti di vario tipo: testi di legge, enciclopedie, documenti storici, ecc. Con la rivoluzione scientifica e industriale dell’età moderna il volume delle informazioni è aumentato in modo esponenziale. L’avvento dei moderni computer ha fornito uno strumento formidabile per la memorizzazione e la ricerca di grandi quantità di dati e informazioni. Negli ultimi anni la rivoluzione informatica, la creazione della rete internet e la diffusione capillare dei computer ha portato alla creazione di motori di ricerca online molto potenti, che in pochi secondi possono accedere ad archivi di documenti presenti sui miliardi di siti web presenti sulla rete.
Possiamo distinguere due grandi categorie di sistemi di Information Retrieval: i sistemi classici e quelli basati sul web.
1.1) I sistemi IR classici
Negli anni ’50 e ’60 del secolo XX sono stati fatti la maggior parte degli esperimenti per sviluppare i primi sistemi IR basati sui computer. Lo sviluppo dell’industria dei computers ha permesso di sostituire i vecchi sistemi manuali di indicizzazione e ricerca con nuovi sistemi automatizzati, che hanno permesso una ricerca molto più veloce delle informazioni. Le interrogazioni degli utenti vengono immesse tramite terminali collegati al sistema informatico; i risultati delle ricerche vengono presentati all’utente in tempo reale sullo schermo del terminale. I primi sistemi erano basati sul Modello Booleano, che analizzeremo nei paragrafi successivi.
Alcune delle caratteristiche principali dei sistemi IR classici sono le seguenti:
- il volume dati in genere è grande, ma controllato;
- i documenti sono classificati, puliti e non duplicati;
- il contenuto è abbastanza statico; una volta che un documento è stato aggiunto alla collezione non cambia;
- anche la dimensione dell’archivio dei documenti è abbastanza statica;
- i documenti non sono connessi tra loro, tranne che tramite dei riferimenti bibliografici.
Molte università, biblioteche, studi legali, enti pubblici e privati utilizzano sistemi di Information Retrieval per fornire accesso a pubblicazioni, libri ed altri documenti.
1.2) I sistemi IR basati sul web
La nascita del World Wide Web ha introdotto un nuovo paradigma nel campo dell’Information Retrieval. La rete mondiale Internet e il Web rappresentano il contenitore di informazioni più grande esistente al mondo, tuttora in continua espansione. Intorno al \(1990\) sono nati i primi motori di ricerca: Yahoo, Google, ecc. In pochi anni Google è diventato il più grande motore di ricerca del mondo. L’algoritmo PageRank di Google utilizza strumenti matematici sofisticati per analizzare i contenuti delle pagine Web, i collegamenti con gli altri siti e per presentare la lista dei documenti in base alla loro rilevanza.
Accanto all’Information Retrieval classico si è sviluppata quindi una nuova branca, chiamata Web Information Retrieval (WebIR).
Alcune delle caratteristiche principali dei sistemi IR basati sul web sono le seguenti:
- il volume dei dati sul web è enorme e difficile da calcolare;
- il contenuto del web è dinamico; in ogni momento ci possono essere modifiche e aggiunte di documenti. Chiunque può pubblicare documenti di vario tipo in ogni momento, da qualunque parte del mondo;
- i documenti non sono strutturati. Non ci sono standards per il contenuto e la struttura dei documenti;
- esistono molte copie o versioni dei vari documenti;
- il formato dei documenti è in genere HTML, XML;
- i documenti sono connessi tramite hyperlinks.
Le caratteristiche dei documenti sul web sono quindi molto diverse da quelle dei sistemi IR tradizionali. Un componente aggiuntivo nei sistemi WebIR è il crawler: si tratta di un software utilizzato per leggere le pagine Web e analizzare le varie tipologie di dati presenti (testi, immagini, video, metadati, ecc.). Il crawler individua i termini e le parole chiavi più ricorrenti e significative creando un database, che servirà poi al processo di indicizzazione. Nella fase di indicizzazione viene creato un database indice che, date le dimensioni della rete internet e del web, ha dimensioni molto grandi. Quando viene effettuata una richiesta di ricerca il motore legge il database indice, ed è in grado di rispondere in tempi molto brevi.
In questo articolo studieremo i sistemi IR classici; in un articolo successivo analizzeremo i sistemi WebIR.
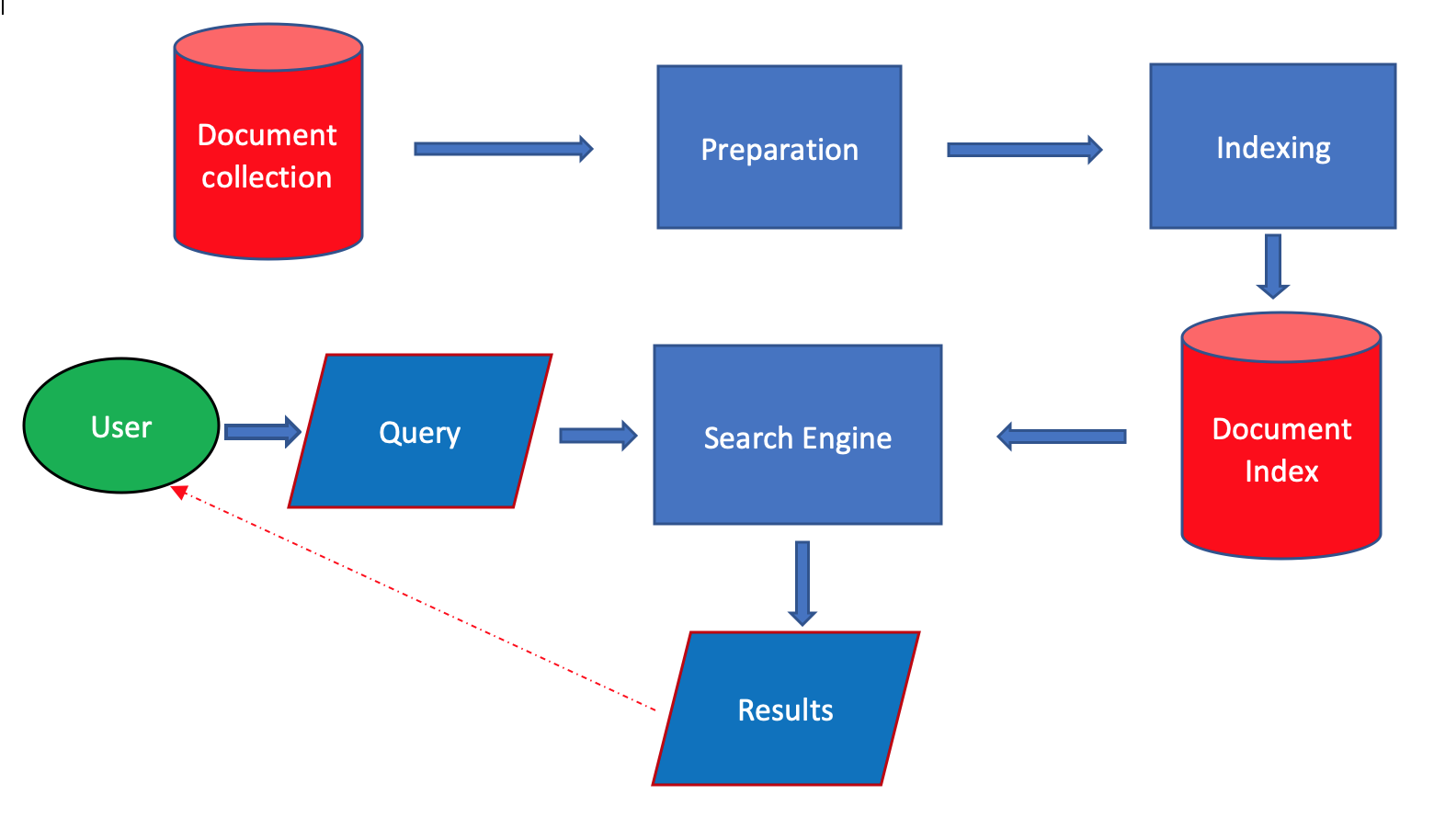
2) L’architettura di un sistema di Information Retrieval classico
I componenti fondamentali di un sistema IR classico sono i seguenti:
- acquisizione e trasformazione dei documenti;
- indicizzazione dei documenti, per creare le strutture necessarie per la ricerca;
- motore di ricerca (search engine);
- interfaccia utente, per l’immissione delle query e la presentazione dei risultati.
2.1) Acquisizione e trasformazione dei documenti
L’analisi dei documenti (parsing) e la tokenizzazione
Questa fase serve per analizzare il contenuto dei documenti e la struttura del testo. Vengono analizzate le singole parole presenti nel testo e la loro frequenza. Oltre alle parole vengono evidenziati altri componenti presenti nei documenti, come le immagini, le tabelle e i metadati, cioè informazioni relative alla struttura e al contenuto dei documenti.
In questa fase viene effettuata la tokenizzazione del documento, cioè il testo viene trasformato in un elenco di token, che diventeranno delle chiavi dell’archivio indice che sarà creato nella fase successiva. Alcune operazioni effettuate in questo processo sono le seguenti:
- eliminazione dei caratteri di punteggiatura
- trasformazione delle maiuscole in minuscole
- divisione delle parole con un trattino
- eliminazione delle cifre contenute nelle parole
Naturalmente il processo di tokenizzazione è abbastanza delicato, in quanto non sempre le operazioni sopra elencate sono prive di conseguenze negative. Eliminando o sostituendo alcuni caratteri o parole in alcuni casi si può perdere una parte importante del contenuto. Ad esempio sostituendo la parola “Apple” con “apple” abbiamo due significati completamente diversi. Il risultato del processo della fase di tokenizzazione è la creazione di una rappresentazione del contenuto e della struttura del documento, che saranno utilizzati nel processo successivo di indicizzazione.
Eliminazione delle stop words
Le stop words sono parole che hanno una frequenza elevata e bassa probabilità di essere utilizzate in una ricerca. Esempi sono gli articoli, le preposizioni, le particelle pronominali. Il concetto è che alcune parole sono più importanti di altre per rappresentare il contenuto di un documento. L’eliminazione delle stop words ha anche il vantaggio di ridurre le dimensioni dell’indice.
Comunque in alcuni casi l’eliminazione delle stop words può causare la perdita di termini chiave che sono importanti per la ricerca. Il problema è che non può esistere una lista standard di stop words, in quanto una parola può avere un significato molto diverso a seconda del contesto che si sta analizzando. Con la disponibilità di computer di grande potenza e memorie di grande capacità, forse in alcuni casi si può ridiscutere sugli effettivi vantaggi derivanti dalla eliminazione delle stop words.
Lo stemming
Le lingue naturali come l’italiano o l’inglese hanno un alto grado di espressività: un singolo concetto può essere espresso in molti modi diversi.
I motori di ricerca devono essere in grado di individuare un concetto rilevante per una query, indipendentemente dal modo in cui viene espresso nei documenti. Non basta cercare documenti che contengono i termini presenti nella query, ma bisogna trovare tutti i documenti che contengono parole diverse ma collegate dal punto di vista semantico, cioè del significato.
Lo stemming è appunto il processo che cerca di individuare le relazioni fra parole differenti. La forma flessa di una parola viene ridotta alla sua radice, chiamata il “tema” della parola.
Esistono vari algoritmi di stemming, che hanno logiche talvolta diverse. Il più comune per la lingua inglese è l’algoritmo di Porter, di cui vediamo alcuni esempi relativi alla lingua inglese:
Per uno studio dell’algoritmo di Porter vedere il seguente link.
Thesauri
Ci sono molti modi per esprimere un concetto (sinonimia). Ad esempio tetto=copertura.
Inoltre spesso una parola ha significati multipli (polisemia). Esempi: riso, albero, radice, ecc.
Un thesaurus è un vocabolario di termini collegati in strutture che permettono di gestire la sinonimia e polisemia, al fine di rendere le ricerche più precise e complete.
2.2) La creazione dell’indice dei documenti
Come abbiamo visto i motori di ricerca dei sistemi IR non operano direttamente sui documenti originali, ma su delle strutture create nel processo di indicizzazione. Tradizionalmente i documenti di una collezione vengono rappresentati tramite un insieme di termini o parole indice. La capacità di memorizzazione dei moderni elaboratori permette in alcuni casi di rappresentare un documento tramite l’intero insieme delle parole in esso contenute; si parla allora di indicizzazione full-text. Per collezioni molto grandi tale tecnica può non essere fattibile; in questo caso si selezionano dei termini chiave mediante i quali viene creato un indice per il motore di ricerca.
Il processo di creazione dell’indice dei documenti legge il testo trasformato nella fase precedente e crea gli indici e le strutture di dati che permettono una ricerca veloce dei documenti. L’insieme di tutti i termini che sono stati indicizzati viene chiamato il vocabolario (document index).
Una delle strutture più utilizzate è l’indice invertito. Sostanzialmente ad ogni termine viene associata una lista contenente gli identificativi dei documenti nei quali il termine è presente.
Esempio 2.1
Supponiamo di voler effettuare delle ricerche sui seguenti quattro documenti:
Una possibile struttura dell’indice invertito è la seguente:
\[ \begin{array}{llll} \hline \text{automobili} & (d1,1),(d3,1),(d4,1) \\ \text{biciclette} & (d2,1),(d3,1),(d4,1) \\ \text{ruote} & (d1,1),(d2,1),(d3,2) \\ \vdots \\ \hline \end{array} \]dove la coppia \((d1,1)\) ad esempio significa che il termine è presente nel documento \(d1\) con frequenza uguale a \(1\).
2.3) Interazione dell’utente con il sistema IR
Immissione della query
L’utente di un sistema IR deve effettuare una richiesta mediante una interrogazione (query) espressa nel linguaggio previsto dal sistema. In genere i linguaggi utilizzano la logica booleana. Una richiesta tipica consiste in uno o più termini separati dagli operatori logici AND, OR, NOT. I sistemi IR più avanzati supportano direttamente il linguaggio naturale per effettuare le interrogazioni.
Trasformazione delle query
Questo processo consiste nell’analizzare le parole immesse dall’utente, correggere eventuali errori e tradurre le parole immesse in token, da utilizzare nella ricerca nell’indice. Sulla query viene anche applicato il processo di stemming e vengono eliminate le stop words, in modo da produrre delle chiavi di ricerca compatibili con i termini dell’archivio indice.
Visualizzazione dei risultati
Questo componente visualizza la lista dei documenti che sono il risultato della ricerca. L’ordine di presentazione in genere dipende dalla rilevanza dei documenti rispetto alle richiesta della query. Il grado di rilevanza di un documento viene calcolato mediante una funzione di similarità, come vedremo nel paragrafo successivo.
3) Modelli classici di Information Retrieval
Un modello di IR fornisce le specifiche dettagliate relative alla struttura e al funzionamento di un sistema IR. In particolare contiene le seguenti informazioni:
- rappresentazione dei documenti
- rappresentazione delle query
- funzione di ricerca ed estrazione (retrieval)
- ordinamento dei risultati della ricerca (ranking)
Dal punto di vista formale un modello è rappresentato da una quadrupla
\[ (D,Q,F,R(q_{i},d_{j})) \]dove
- \(D\) rappresenta la collezione dei documenti
- \(Q\) è l’insieme delle query, con le quali gli utenti immettono le loro richieste
- \(F\) specifica la modalità di rappresentazione dei documenti e delle query
- \(R(q_{i},d_{j})\) è la funzione di ordinamento (ranking) che associa un punteggio (un numero reale), che misura il grado di similarità tra la query \(q_{i}\) e il documento \(d_{j}\)
Lo scopo principale di un sistema IR è di estrarre tutti i documenti rilevanti e nello stesso tempo non estrarre quelli non rilevanti. Il concetto di rilevanza serve per determinare quanto bene un documento soddisfa le necessità informative dell’utente, espresse tramite una query. La nozione di rilevanza può essere discreta (ad esempio binaria) oppure continua, con vari gradi di rilevanza.
Due parametri importanti per misurare la bontà dei risultati di una ricerca sono la precisione (\(P\)) e la completezza o recall (\(R\)):
Definiamo i seguenti simboli:
\[ \begin{split} TP: & \text{ veri positivi} \\ FP: & \text{ falsi positivi} \\ TN: & \text{ veri negativi} \\ FN: & \text{ falsi negativi} \\ \end{split} \]La precisione e la completezza possono essere calcolate mediante le seguenti formule:
\[ \begin{array}{l} P = \dfrac{TP}{TP+FP} \\ R = \dfrac{TP}{TP+FN} \\ \end{array} \]La seguente tabella illustra la situazione:

In genere c’è una relazione inversa fra la precisione e la completezza: se diminuiscono i falsi positivi, e quindi aumenta la precisione, allora diminuiscono anche i veri positivi e aumentano i falsi negativi, causando una diminuzione della completezza.
Analizziamo ora i principali modelli utilizzati nei sistemi classici di information retrieval, nei quali i documenti contengono in genere testo non strutturato.
4) Il modello booleano
Uno primi modelli utilizzati nei sistemi IR tradizionali è il modello booleano, basato sulla teoria degli insiemi e l’algebra booleana. L’algebra booleana è un sistema di regole definito dal matematico inglese George Boole (1815-1864) per dare una sistemazione rigorosa al sistema della logica sviluppato da Aristotele (384 A.C-382 A.C). Gli elementi base della logica di Aristotele sono le proposizioni, cioè frasi che possono assumere solo due valori: vero oppure falso. Combinando diverse proposizioni abbiamo delle espressioni complesse; le regole della logica servono a stabilire se queste espressioni sono vere o false.
Boole nel \(1854\) ha formalizzato il sistema logico di Aristotele nella sua opera ‘An Investigation of the Laws of Thought‘[1].
Date due proposizioni \(A,B\), le operazioni logiche fondamentali nell’algebra booleana sono le seguenti:
- intersezione o prodotto logico, indicata con \(A \land B\)
- unione o somma logica, indicata con \(A \lor B\)
- complemento o negazione logica, indicata non \(\neg A\)
L’espressione \(A \land B\) è vera se \(A,B\) sono entrambe vere, altrimenti è falsa. L’espressione \(A \lor B\) è vera se almeno una delle due è vera, altrimenti è falsa. L’espressione \(\neg A\) è vera se \(A\) è falsa e viceversa.
Nel mondo della programmazione vengono usati anche altri simboli per le tre operazioni: “&” oppure “and” per il prodotto, “|” oppure “or” per la somma, “!” oppure “not” per la negazione.
Ricordiamo alcune delle principali leggi dell’agebra booleana. Siano \(A,B,C\) delle proposizioni:
Uno strumento utile per verificare il valore logico di una proposizione composta è rappresentato dalle tavole di verità. Di seguito vediamo le tavole di verità relative al prodotto e alla somma di due proposizioni \(A,B\):
\[ \begin{array}{|c c|c|c|} A & B & A \land B & A \lor B \\ \hline T & T & T & T\\ T & F & F & T\\ F & T & F & T\\ F & F & F & F\\ \end{array} \]Esercizio 4.1
Mediante le tavole di verità dimostrare le seguenti leggi di De Morgan:
Per approfondire lo studio dell’algebra booleana e le sue applicazioni vedere [2].
Il modello booleano per l’information retrieval ha queste caratteristiche principali:
- un documento è rappresentato tramite un insieme di termini o parole chiave, che rappresentano il contenuto essenziale del documento;
- le query dell’utente sono delle espressioni booleane che utilizzano le parole chiave, connesse mediante gli operatori logici booleani (AND, OR, NOT);
- il risultato della ricerca è un insieme di documenti rilevanti rispetto alla query;
- la decisione sui documenti rilevanti è di tipo binario (SI/NO). Vengono estratti i documenti che soddisfano i criteri di ricerca al 100%. Non vengono estratti documenti che soddisfano parzialmente la ricerca.
Esempio 4.1
Supponendo di avere tre termini \(t_{1},t_{2},t_{3}\), alcune query sono le seguenti:
La seconda query ad esempio estrae tutti i documenti nei quali è presente il termine \(t_{1}\) e contemporaneamente è presente almeno il termine \(t_{2}\) oppure il termine \(t_{3}\).
Gli utenti in genere utilizzano i simboli \(AND, OR, NOT\) per gli operatori.
4.1) Limitazioni del modello booleano
Il modello booleano ha diverse limitazioni:
- poca flessibilità: la strategia di ricerca è basata su un criterio di decisione binario (un documento viene considerato rilevante o non rilevante)
- la richiesta degli utenti deve essere tradotta nel linguaggio booleano, che molti utenti non esperti trovano difficile e non naturale;
- le query preparate da utenti non esperti spesso sono troppo semplicistiche;
- i documenti non vengono ordinati in base alla rilevanza.
Nonostante le sue limitazioni, il modello booleano è tuttora ampiamente diffuso nei sistemi presenti sul mercato.
4.2) Estensione del modello booleano
Per superare i limiti del modello booleano classico sono state proposte varie estensioni. Una proposta consiste nell’aggiungere agli operatori booleani di base (AND, OR, NOT) alcuni operatori addizionali. Ad esempio l’operatore di prossimità, che serve per specificare nella query che due termini debbano presentarsi vicini nel documento. La distanza fra due termini può essere misurata dal numero di parole presenti nell’intervallo.
Un’altra proposta cerca superare il criterio di selezione binario (SI/NO) e permettere l’ordinamento (ranking) dei documenti rilevanti estratti. Sostanzialmente ad ogni termine viene assegnato un peso, in genere compreso nell’intervallo \([0,1]\), con una logica simile al modello vettoriale che vedremo di seguito.
Per maggiori informazioni vedere il libro [3].
5) Il modello vettoriale
Il modello vettoriale cerca di superare alcuni dei limiti del modello booleano. Il principio base di questo modello è che il contenuto semantico di un documento può essere rappresentato mediante i suoi termini chiave.
Supponiamo di avere una collezione di \(n\) documenti nella quale sono presenti \(m\) termini chiave. Possiamo definire un vettore a \(m\) dimensioni come una stringa di \(m\) numeri reali. Ad ogni documento associamo un vettore; ogni numero presente nel vettore rappresenta la frequenza di ognuno degli \(m\) termini chiave presenti nel documento associato.
Le caratteristiche principali del modello vettoriale sono le seguenti:
- i documenti e le query sono rappresentati come vettori in uno spazio \(m\)-dimensionale euclideo, dove ad ogni termine viene assegnata una separata dimensione;
- ogni elemento di un vettore rappresenta la frequenza di uno dei termini chiave nel documento associato;
- ogni ricerca viene eseguita calcolando il grado di similarità tra il vettore che rappresenta la query e i vettori che rappresentano i singoli documenti;
- i documenti con un alto grado di similarità con la query sono quelli ai quali è assegnata la maggiore rilevanza per l’utente.
Diamo ora una definizione formale del modello vettoriale.
Definizione 5.1 – Il modello vettoriale
Supponiamo di avere un insieme di \(n\) documenti \(D\):
Indichiamo con \(T\) l’insieme degli \(m\) termini (parole chiave o semplici parole) presenti nella collezione di documenti:
\[ T=\{T_{1},T_{2}, \cdots, T_{m}\} \]Ad ogni documento \(D_{i}\) viene assegnato un vettore di numeri reali \(\mathbf{w_{i}}\), chiamati pesi, nel seguente modo:
\[ \mathbf{w_{i}}= (w_{1i},w_{2i}, \cdots, w_{mi}\} \]con \(0 \le w_{ki}\le 1\).
Possiamo rappresentare il modello tramite la seguente matrice:
L’elemento \(w_{ij}\) rappresenta la frequenza pesata del termine \(T_{i}\) nel documento \(D_{j}\).
Analogamente una query è rappresentata con un vettore \(\mathbf{q}\)
dove ogni elemento \(q_{k}\) esprime il peso che il termine \(T_{k}\) ha in relazione alle necessità informative dell’utente che sottomette la query.
Naturalmente la determinazione del valore dei coefficienti \(w_{ij}\) è un problema complesso, con aspetti sia linguistici sia semantici.
5.1) La misura di similarità
Una volta calcolati i vettori corrispondenti ai documenti e alla query, è possible determinare la distanza fra la query e ogni documento. Una misura di similarità è una funzione utilizzata per determinare la vicinanza fra una query e un documento. Possiamo dare una definizione formale del concetto di similarità, per misurare il grado di similitudine fra due vettori.
Definizione 5.2
Una funzione \(\sigma: D \times D \to [0,1]\) viene chiamata una metrica di similarità se valgono le seguenti proprietà:
Data quindi una query \(q\) possiamo definire l’insieme dei documenti rilevanti \(R(q)\), fissando una determinata soglia \(\alpha\),
\[ R(q)=\{d \in D|\sigma(d,q) \gt \alpha \} \]Sono possibili diverse possibilità per definire la metrica di similarità. In genere si utilizza un valore normalizzato, compreso nell’intervallo \([0,1]\), per esprimere il grado di relazione fra una query e un documento. Una metrica molto utilizzata è basata sul prodotto scalare tra due vettori.
Definizione 5.3 – Prodotto scalare
La similarità tra un documento \(D_{k}\) e una query \(q\) è la seguente:
dove \(w_{ik}\) è il peso del termine \(T_{i}\) nel documento \(D_{k}\) e \(q_{i}\) è il peso del termine \(T_{i}\) nella query \(q\).
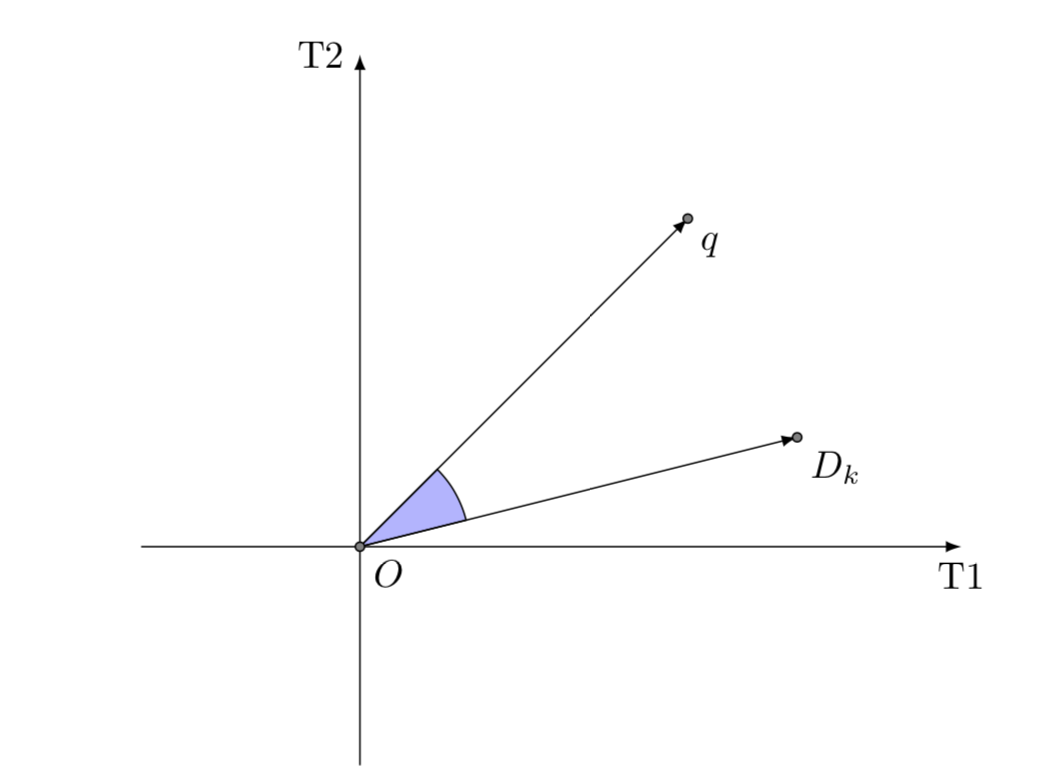
Si può normalizzare il prodotto scalare rispetto alla norma, ottenendo il coseno dell’angolo fra i due vettori:
\[ \cos \sigma(D_{k},q) = \frac{ \sum\limits_{i=1}^{m}w_{ik}q_{i}}{\sqrt{\sum\limits_{i=1}^{m}w_{ik}^{2}}\sqrt{\sum\limits_{i=1}^{m}q_{i}^{2}}} \]5.2) Criterio di ranking
L’utilizzo di una misura di similarità permette di ordinare e presentare i documenti estratti in base alla rilevanza, e impostare una soglia al disopra della quale scartare i documenti.
5.3) La pesatura dei termini
Il fattore tf
La frequenza di un termine in genere è collegata alla sua importanza per il contenuto del documento. Indichiamo con \(f_{ij}\) la frequenza del termine \(T_{i}\) nel documento \(D_{j}\). Il fattore \(tf_{ij}\) normalizzato è il seguente:
La frequenza inversa dei documenti
Indichiamo con \(df_{i}\) il numero dei documenti che contengono il termine \(T_{i}\). Normalizzando abbiamo la frequenza inversa
Se \(df_{i}=N\) allora \(idf_{i}=0\).
Questo parametro è una misura dei termini che appaiono in molti documenti, e quindi sono meno significativi per il contenuto (ad esempio gli articoli, le preposizioni, ecc.).
Schema di pesatura tf-idf
Uno degli aspetti più critici per un sistema IR è l’assegnazione dei pesi \(w_{ij}\) nella matrice dei documenti e dei termini.
Lo schema tf-idf calcola i coefficienti \(w_{ij}\) della matrice dei pesi secondo questa formula:
Esistono molte altre varianti, ognuna della quali cerca di migliorare i parametri di precisione e completezza di un sistema IR.
5.4) Considerazioni sul modello vettoriale
Alcuni dei punti di forza del modello vettoriale sono i seguenti:
- è possibile discriminare il valore semantico dei vari termini mediante l’assegnazione dei pesi \(w_{ij}\);
- l’assegnazione dei pesi alle query permette di rappresentare accuratamente le richieste necessità dell’utente;
- la funzione di similarità è uno strumento semplice e potente per determinare il grado di rilevanza di un documento rispetto ad una query;
- la funzione di similarità permette di presentare i documenti secondo il grado di rilevanza.
Limitazioni del modello vettoriale
Naturalmente il modello vettoriale ha anche punti deboli. In particolare ricordiamo i seguenti:
- la determinazione dei pesi dei termini non è formalmente definita ma è lasciata all’intuizione e all’esperienza;
- si assume che i termini siano indipendenti fra loro, non considerando quindi eventuali relazioni;
- non viene analizzato il contenuto a livello semantico. Non risolve il problema dei sinonimi e della polisemia;
- non viene analizzata la sintassi, cioè la struttura della frase, l’ordine delle parole, ecc.;
- l’ordine nel quale i termini appaiono nei documenti viene perso nella presentazione;
- non è possibile distinguere i documenti nei quali i termini sono vicini tra loro da quelli nei quali sono lontani.
6) Il modello probabilistico
Il modello probabilistico è stato introdotto nel 1960 da Maron e Kuhns, nella loro pubblicazione ‘On Relevance, Probabilistic Indexing and Information Retrieval’[4].
L’idea base è di assegnare una probabilità \(P(T|D)\) ad ogni termine in un documento, invece di applicare una decisione binaria (SI/NO). Il valore \(P(T|D)\) rappresenta la probabilità che un utente utilizzi il termine \(T\) in una ricerca sul documento \(D\).
Prima di esporre il modello probabilistico ricordiamo il famoso teorema di Thomas Bayes (1701-1761), che permette di calcolare la probabilità condizionata di un evento \(A\), dato che si è verificato un evento \(B\).
Teorema 6.1 – Bayes
Dati due eventi \(A,B\), con \(P(B) \neq 0\), si ha
Ovviamente se l’evento \(A\) è indipendente dall’evento \(B\) allora \(P(A|B)=P(A)\).
Torniamo ora al modello probabilistico. Il modello utilizza uno schema binario:
- ogni documento è rappresentato con un vettore \(d=(d_{1}, \cdots, d_{m})\), dove \(d_{k}=1\) se il termine \(t_{k}\) è presente nel documento, altrimenti vale \(0\);
- i termini occorrono nei vari documenti in modo indipendente.
I principali parametri del modello sono i seguenti:
- \(R\), l’insieme dei documenti rilevanti per una query \(q\);
- \(\overline{R}\), l’insieme dei documenti irrilevanti per una query \(q\);
- \(P(R|D_{k},q)\), probabilità che il documento \(D_{k}\) sia rilevante per la query \(q\);
- \(P(\overline{R}|D_{k},q)\), probabilità che il documento \(D_{k}\) sia non rilevante per la query \(q\);
- \(P(R,q)\), probabilità che un documento scelto a caso sull’intero archivio sia rilevante per la query \(q\);
- \(P(\overline{R},q)\), probabilità che un documento scelto a caso sull’intero archivio sia non rilevante per la query \(q\);
- \(P(D_{k}|R,q)\), probabilità di scegliere un documento \(D_{k}\) nell’insieme \(R\);
- \(P(D_{k}|\overline{R},q)\), probabilità di non scegliere un documento \(D_{k}\) nell’insieme \(\overline{R}\).
La funzione di similarità \(\sigma\) è definita nel seguente modo:
\[ \sigma(D_{k},q)= \frac{P(R|D_{k},q)}{P(\overline{R}|D_{k},q)} \]Utilizzando il teorema di Bayes, possiamo scrivere
\[ \sigma(D_{k},q)= \frac{P(D_{k}|R,q)P(R,q)}{P(D_{k}|\overline{R},q)P(\overline{R},q)} \]Notiamo che il rapporto \(\dfrac{P(R,q)}{P(\overline{R},q)}\) è costante per ogni documento e ogni query.
Ad ogni documento \(D_{k}\) viene assegnato un vettore di numeri binari (\(0,1)\) che indicano la presenza o assenza dei termini nel documento:
Si assume che i termini siano indipendenti. La funzione di similarità può quindi essere scritta applicando le probabilità dei singoli termini. Ad esempio
\[ P(D_{k}|R,q) = \left(\prod\limits_{T_{i}|w_{ik}=1}P(T_{i}|R,q)\right) \times \left(\prod\limits_{T_{i}|w_{ik}=0}P(\overline{T_{i}}|R,q)\right) \]dove \(P(T_{i}|R,q)\) e \(P(\overline{T_{i}}|R,q)\) indicano rispettivamente le probabilità che il termine \(T_{i}\) sia o non sia presente in un documento scelto a caso dell’insieme \(R\). In modo simile si calcola \(P(D_{k}|\overline{R},q)\).
6.1) Considerazioni sul modello probabilistico
Un vantaggio importante del modello probabilistico è che i documenti vengono presentati in ordine decrescente di probabilità di rilevanza. Tuttavia il modello presenta delle limitazioni importanti, tra le quali le seguenti:
- è necessario effettuare una stima iniziale delle probabilità \(P(T_{k}|R)\);
- l’assunzione dell’indipendenza dei termini è un’approssimazione troppo drastica, che in genere fa perdere parte del contenuto del testo;
- non si considera la frequenza dei termini in un documento, ma si applica una logica binaria.
7) Cenni ai sistemi multimediali e al gap semantico
Il formato testuale dei documenti ha tuttora un ruolo predominante nei sistemi di information retrieval.
Tuttavia una parte importante delle informazioni nei vari settori della scienza, della tecnologia e delle scienze umane è registrata in documenti che hanno anche un contenuto diverso dal formato testuale: immagini, video, audio, grafica 3D.
Esiste una grande esigenza di accedere alle informazioni non testuali in molte professioni: medicina, architettura, ingegneria, ecc.
Per soddisfare queste esigenze negli ultimi anni sono stati sviluppati i primi sistemi di information retrieval multimediali (MIR), in grado di elaborare anche dati non testuali. I principali motori di ricerca sul web (Google, Bing, ecc.) offrono già alcune di queste funzionalità.
Il grande sviluppo della tecnologia elettronica ha messo a disposizione computer di grande potenza, grande disponibilità di memoria e reti di trasmissione molto veloci; queste caratteristiche sono indispensabili per elaborare la grande quantità di dati necessaria per registrare i dati multimediali.
Tuttavia la potenza elaborativa dei computer e delle reti di trasmissione non è sufficiente per lo sviluppo di sistemi MIR sufficientemente sofisticati. La ricerca di informazioni su documenti multimediali ha un livello di complessità molto superiore rispetto ai classici sistemi testuali, non solo dal punto di vista tecnologico ma soprattutto dal punto di vista concettuale.
La possibilità di realizzare motori di ricerca su contenuti multimediali si è scontrata con una barriera semantica. Come è noto le immagini hanno un contenuto informativo molto maggiore dei testi (“una immagine vale più di mille parole“). Inoltre il significato di un’immagine ha un livello di indeterminatezza maggiore rispetto al significato di una parola o di una frase. Per questi motivi è molto difficile, forse impossibile, estrarre da una immagine un insieme di caratteristiche (feature) elementari che possano rappresentarne completamente il contenuto semantico.
Le feature di basso livello di una immagine (colore, sfumatura, ecc.) in genere non sono sufficienti per rappresentare il significato ad alto livello dell’immagine, che il nostro cervello riesce a percepire. Questo problema prende il nome di gap semantico.
Per una panoramica sullo stato dell’arte vedere il libro di Neto[3].
Intelligenza artificiale e barriera semantica
Il problema della barriera semantica esiste in tutti i campi dell’Intelligenza Artificiale (AI), come la traduzione automatica delle lingue o la guida automatica di veicoli. Nonostante i progressi importanti raggiunti, non si è ancora in grado neanche lontanamente di raggiungere le abilità del cervello umano per gestire le situazioni veramente difficili (ad esempio tradurre una frase complessa oppure gestire la guida automatica in una situazione caotica tipica delle grandi città).
Per avvicinarsi ai livelli del cervello umano, si devono creare sistemi in grado di avere la consapevolezza delle situazioni di cui fanno esperienza e di comprenderne il significato globale, che non è derivabile facendo la somma delle feature elementari. Il cervello umano ha una complessità infinitamente superiore e non lavora in modo digitale; per molti aspetti il funzionamento del cervello è tuttora sconosciuto. Sicuramente per emulare il cervello umano dovranno essere modificati i paradigmi attuali, basati sull’utilizzo massiccio della tecnologia digitale e di grandi moli di dati.
Conclusione
I sistemi di Information Retrieval hanno conosciuto un grandissimo sviluppo, grazie soprattutto alla disponibilità di computer sempre più potenti. Ormai sono una necessità indispensabile nei vari settori di attività delle società moderne.
L’avvento del web ha creato un cambio di paradigma nella struttura e nel funzionamento dei motori di ricerca. Quando le informazioni da ricercare sono contenute nella rete mondiale del Web le problematiche cambiano completamente:
- la collezione è dinamica, molto variabile nel tempo
- le dimensioni sono enormi
- i documenti non sono sempre disponibili
- le query degli utenti sono ancora più imprecise e vaghe
In un prossimo articolo studieremo i sistemi di ricerca delle informazioni presenti sul Web.
Bibliografia
[1]G. Boole – An Investigation of the Laws of Thought, on Which are Founded the Mathematical Theories of Logic and Probabilities (Benediction Classics)
[2]E. Mendelson – Schaum’s Outline of Boolean Algebra and Switching Circuit (McGraw-Hill)
[3]Yates, Neto – Modern Information Retrieval (Addison Wesley)
[4]Maron, Khuns – Journal of the Association for Computing Machinery (v. 7, n. 3, July 1960, p. 216-244)
0 commenti